
Finding the cheapest book with AWS Lambda
BookDepository is well-known online book seller that belongs to Amazon. Nevertheless, book prices are sometimes cheaper than Amazon, since in contrast to Amazon BookDepository offers free delivery worldwide. Although I have been buying books with BookDepository for more than 7 years, I never really thought about what free delivery meant until recently. A couple of months ago, I was planning to buy the book Designing Data-Intensive Applications : The Big Ideas Behind Reliable, Scalable, and Maintainable Systems (it’s an awesome book by the way) and I thought of checking if the price of this book is different based on the my IP when I access BookDepository. So I used a VPN to login to BookDepository from Germany, as well as USA. The prices were different as you can see in the screenshots below. Buying the book from the USA the book costs $28.47, while from Germany (by converting euros to dollars) the book costs $36.31. So, I just went ahead and ordered the book using an American IP but by still delivering the book to a European address, thus saving $7.84. Whether or not this was a moral thing to do is debatable and you can decide on your own.


In other words, BookDepository offers free delivery by incorporating the cost of the delivery in the price of the book. In hindsight this seems obvious and it has also been widely known. Nevertheless, I became curious and I decided to answer the following two questions:
- From which country can we most likely get the cheapest book? (TL;DR South Korea)
- Are there books where the difference in price between different countries is extremely high (e.g., > $1000)? (TL;DR found a book with a difference of more than $5000)
To answer the aforementioned questions I decided I would go through 100,000 books and check the price of each book in different countries. This raises two subsequent questions: (i) How can we get different prices of a book depending on the country? and (ii) How can I get the URLs of 100,000 books. In what follows, I explain how I tackled issues.
Finding the prices using AWS Lambda
Assume we are given the URL of a book (e.g, https://www.bookdepository.com/Designing-Data-Intensive-Applications-Martin-Kleppmann/9781449373320) and we want to get a list of prices this book has in different countries. One way would be to fire up a VPN, connect from different countries, and write down the price of the book in each country. Naturally, such an approach would not scale for 100,000 books. Somebody could argue, that if I had the 100,000 book URLs I could just fire up a VPN, connect (let’s say) from an American IP, get the prices of all the books from this American IP in an automated way, then connect from a German IP, etc. Such an approach could be automated and it would work fine. In any case, VPN services usually are costly (i.e., a few bucks a month), therefore I didn’t want to follow such an approach. Additionally, I wanted to create an application that could give me the country where I can get the cheapest price for a book. Maybe I would like to use such an application in 3 months from now and I was not really in the mood of getting a yearly VPN subscription just for this.
I was not planning to use a VPN service, I thought I could utilize Amazon EC2 instances, since they are offered in multiple regions (e.g., Frankfurt, London, etc.). In such a scenario, I would launch an instance in each possible region. Each instance will execute an application that given the URL of a book, connects to BookDepository, gets the price and returns it. Since instances reside in different regions I would get the prices for different countries. Still, such an approach has the issue that I would either need to have the instances always up and running which would work fine If I want to find the prices of 100,000 books. But if I want to find the prices of a book 3 months from now I would either need to have all instances up and running for 3 months which would be expensive, or launch and terminate the instances to just find the prices of a single book which would be expensive as well. For example, let us say I launch 10 total t2.nano instances in 10 different regions, even if I use them for 1 minute before I terminate them I would still need to pay $0.067.
Since I just wanted to get the price of the book, my problem seemed to perfectly fit the serverless paradigm. So, I decided to use AWS Lambda. The main idea behind AWS Lambda is that we create a lambda function that we upload to Amazon and then we can simply call this function without having to care on which server the function executes. For example, we can write a Java method, then we pack everything into a JAR, upload the JAR to Amazon and we can start calling our method. The cost of a lambda function depends on the memory it consumed, as well as the time it needed to execute. For instance, assuming a lambda function consumes 128MBs and takes 100ms to execute, we need to pay $0.000000208. In other words, if we have 10 regions and execute a lambda function once in each region, we will pay $0.00000208, which is substantially cheaper than the aforementioned $0.067. For finding the prices of multiple books, the price difference between using EC2 and AWS Lambda is not that big. For example, for 100,000 executions of the lambda function we would pay $0.208, while if we used EC2 instances we would need 100,000 * 100ms (~3hours) so we would pay 3 * $0.067 = $0.201.
AWS Lambda allows the function to be created in a number of languages including Java 8, C# (.NET Core 2.1), Go (1.x), and Python 3.6. For my purposes I used Java with IntelliJ IDEA so I’ll describe the steps on how to deploy an AWS Lambda function using these tools. It should not be extremely different if you use something else. First of all, we create a new Maven project. Then, we are going to use the jsoup Java library to get the price of a book from BookDepository URL, therefore add the following dependency on your pom.xml file.
<dependencies>
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.8.3</version>
</dependency>
</dependencies>
By checking the page source of a BookDepository, we can notice that the price of the book is included here <span class="sale-price">US$32.70</span>. Therefore, with the following code
public class BookPriceFinder {
public String getBookPrice(String URL) throws IOException {
Document doc = Jsoup.connect(URL).get();
Elements salePrice = doc.select("span.sale-price");
return salePrice.get(0).text();
}
public static void main(String[] args) {
String URL = "https://www.bookdepository.com/Designing-Data-Intensive-Applications/9781449373320";
try {
System.out.println(new BookPriceFinder().getBookPrice(URL));
} catch (IOException e) {
System.err.println("Couldn't retrieve the prive of the book in URL: " + URL);
e.printStackTrace();
}
}
}
we can retrieve the price of a book. To make the above code AWS Lambda compatible we need to introduce an extra dependency:
<dependency>
<groupId>com.amazonaws</groupId>
<artifactId>aws-lambda-java-core</artifactId>
<version>1.2.0</version>
</dependency>
Then, we have to change the class to implement RequestHandler<String, String>. This means that our function will get something of type String and return something of type String.
We would also need to introduce (@Override) the method handleRequest
@Override
public String handleRequest(String input, Context context) {
// TODO
return null;
}
This will be the AWS function and it takes an input and returns a String. The context can provide your function with useful information regarding its AWS Lambda execution environment such as the memory limit, remaining time to execute, etc. We do not have to use this parameter, since our function was pretty simple. So, now our Java code would be something like this:
public class BookPriceFinder implements RequestHandler<String, String> {
public String getBookPrice(String URL) throws IOException {
Document doc = Jsoup.connect(URL).get();
Elements salePrice = doc.select("span.sale-price");
return salePrice.get(0).text();
}
@Override
public String handleRequest(String input, Context context) {
try {
return getBookPrice(input);
} catch (IOException e) {
return "There was an error in getting te price of the book: " + e.getMessage();
}
}
}
To upload our method to AWS Lambda, we will first need to pack everything into a JAR file that will also include all the dependencies. This can be done by adding a build tag in your pom.xml file as described here and as seen below:
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.3</version>
<configuration>
<createDependencyReducedPom>false</createDependencyReducedPom>
</configuration>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
Now, you need to deploy your code. To do so, go to “AWS Lambda Management Console” and click on “Create Function” as shown below:
Then, give a name to your function, choose “Java 8” for your runtime and create a custom rule and click create function (see below).
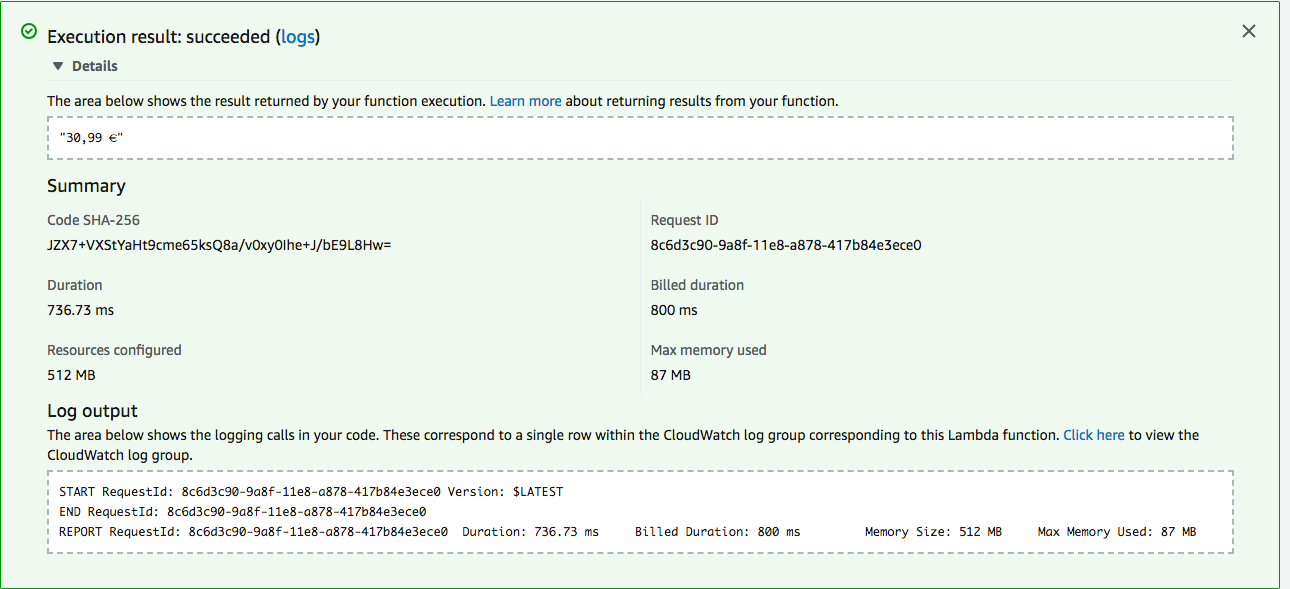
Go to the “Function Code” panel, upload your JAR file and for the Handler you need to write package.class::handlerMethod. For example, if your BookPriceFinder resided in the com.foo.bar package then you will have com.foo.bar.BookPriceFinder::handleRequest. You can test that you can call your function just fine by clicking “Test” on the top right of the management console and then giving as input just a BookDepository URL (e.g., "https://www.bookdepository.com/Designing-Data-Intensive-Applications-Martin-Kleppmann/9781449373320"). Create the test and click “Test”. You will see the result of the the executed function as below:
Note that the AWS web interface is horrific, so if you want to deploy the same function to different regions you will need to go through each one of them, upload your JAR file, etc. There should be easier ways to do this if you are willing to spend sometime getting accustomed to libraries such as the boto library.
Finally, there are many ways to call your AWS Lambda function. One way is to create an API Gateway so you can issue a GET request and get the price of a book. I’m not going to go into details on how to do this but you can have a look a this nice guide. The API Gateway is the approach I used.
Scraping BookDepository
After deploying my lambda function in 12 regions, I could easily write a small Python script that given the URL of a book, it returned the price of each book in each region (I found the Python requests library pretty easy to use to issue HTTP GET requests). Now, I just had to find 100,000 book URLs to check the prices of each book. To do this, I had to crawl and scrap BookDepository. Fortunately, there exists many easy-to-use and good libraries for this. An especial nice and powerful one is Python’s Scrapy that has an excellent documentation to get you started. I just had to write the following code and I was ready to start getting BookDepository URLS for books:
import scrapy
from scrapy.spiders import CrawlSpider, Rule
from scrapy.linkextractors import LinkExtractor
bookDepositoryURL = 'https://www.bookdepository.com/'
class BookDepositorySpider(CrawlSpider):
name = "books"
allowed_domains = [ 'www.bookdepository.com' ]
start_urls = [
bookDepositoryURL
]
rules = (
Rule(LinkExtractor(), callback='parse_item', follow=True),
)
def parse_item(self, response):
for book in response.css('div.book-item'):
yield {
'url': book.css('div.item-img a::attr("href")').extract_first(),
}
print(bookDepositoryURL + book.css('div.item-img a::attr("href")').extract_first())
next_page = response.css('div.item-img a::attr("href")').extract_first()
if next_page is not None:
yield response.follow(next_page, self.parse)
BookDepository starts blocking your requests if you issue to many the one after the other. To solve this I set the [DOWNLOAD_DELAY(https://doc.scrapy.org/en/latest/topics/settings.html#download-delay) to 0.25. If you do not want to use your personal computer to crawl BookDepository you can utilize a service such a Scrapy Cloud, you just upload your Scrapy code and they take care of the rest, although I found Scrapy Cloud to be a bit expensive (9$ per month).
Results
After getting 100,000 book URLS and checking the price of each book from 12 different Amazon regions, I could finally answer my questions.
The average price (all prices are in USD - I used the forex-python library to covert other currencies to USD) of the 100,000 books per regions is depicted below.
| region | price (in USD) |
|---|---|
| seoul | 36.76 |
| singapore | 36.87 |
| frankfurt | 36.94 |
| ireland | 36.95 |
| canada | 37.07 |
| california | 37.89 |
| london | 37.92 |
| paris | 39.92 |
| sydney | 41.78 |
| sao paulo | 41.94 |
| mumbai | 43.66 |
| tokyo | 66.23 |
The biggest difference between two regions that I found was of $5298.33 between California and Tokyo for the book “Semiconductor Quantum Structures - Growth and Structuring”, as shown below.


Finally, note that I used 12 regions since I only took into account N. California for a region from the United States. It might be the case that BookDepository also charges differently in the same country depending on the city somebody resided. This might be interesting to look at. Also, note that the presented prices might have changed at the time you are reading this.
The whole experiment took more time than expected. Some things although seemed easy at first can be tricky to get right. For example, reading prices can be complicated since commas and periods might have a different meaning depending on the country.
I hope my post gave you an idea on what AWS Lambda is and convinced you to spend some time before buying a book from a BookDepository.